Motivation
Over the last few weeks I have begun work on a project I am calling Figment. I’m not quite ready to talk about Figment publicly yet but I do want to write up some of the more interesting things I have been working on in the process.
One of the core features I wanted in Figment was for multiple users to be able to edit text collaboratively a la Google Docs. It turns out this problem is extremely hard. This post is a brief write up of how I arrived at a robust solution.
Prior art
I consider myself a pretty competent engineer but I know enough to know what I don’t know. Collaborative editing is what I consider one of the big four problems in modern computer science along with cache invalidation, and off by one errors ;^). I knew after some pretty quick research that any efforts of mine to build this well would have to be built on the shoulders of either:
- Operational transform
- This is what Google Docs uses. It relies on a central server to handle conflicts to ‘transform’ an edit operation to take into account the result of any previously applied editing operations.
- While this approach clearly works at (google) scale, it has some significant issues.
- For one it requires a central server to keep track of the order of changes, potentially transform the changes, and then keep all the clients in sync. This is kind of a pain to implement but not disqualifying by itself.
- The big problem that ruled OT out for my use case was the requirement that all users currently editing a doc have to be connected to the same backend instance. I don’t want to have the responsibility of keeping track of and routing websocket connections to the right place, nor do I particularly want to figure out how to mitigate the need for infinite vertical scaling that increases linearly with users connected to a certain document. I haven’t really put a lot of thought into the worse case complexity for such a situation but I have to imagine it’s pretty bad.
- The other big (relatively) new player in this field are CRDT’s (what I ended up with)
- At a super high level CRDT’s solve the problem where you have y-replicas (a replica can be either a client or server) who each need to store the state of the document (the clients for display and manipulation, the server for persistence) but you can’t guarantee the order that updates will be received by any given replica. CRDT’s describe how to cordinate the replicas to always arrive at a consistent state, regardless of the order updates are received and applied.
- I’m writing another post about the mathematical assurances CRDT’s offer but for now all you need to know is that CRDT’s are ostensibly a list of (commutative) operations that when applied to each other build up the shared data-type (rich text).
For CRDT’s in the web ecosystem the obvious choice was yjs written by the extraordinarily impressive Kevin Jahns (@dmonad). yjs defines a series of CRDT’s using the YATA algorithm (the original paper was coauthored by Jahns himself). In yjs everything is a list, each CRDT is an abstraction layer built on top of the list.
For example here is a grossly simplified example of how yjs would store the text ‘hello world’
h->e->l->l->o-> ->w->o->r->l->dMy implementation
While the yjs core implementation is largely complete and stable the ecosystem surrounding it is still in it’s relative infancy. One of the features that yjs offers is something called subdocuments which allows you to embed documents in each other. Figment makes use of this heavily. Unfortunately none of the yjs providers (what implements sending yjs updates over a given transport method–websocket, webrtc, etc) support subdocuments as first class citizens, which is a problem since I make heavy use of both subdocuments and y-websocket. The documentation explains:
The providers can sync collections of documents in one flush instead of having multiple requests. It is also possible to handle authorization over the folder structure. But all official Yjs providers currently think of sub-documents as separate entities.
I decided pretty quickly that opening a new websocket connection per subdocument was untenable, each page can have theoretically hundreds of subdocuments. Having hundreds of websocket connections was not an option so I decided to implement the suggestion from the yjs docs of syncing all the subdocuments over a single multiplexed connection.
The binary format defined for sending yjs updates over the wire is pretty simple:
VarUint: messageType
messageSync:
VarUint: messageType
messageYjsSyncStep1:
VarUint8Array: encodedStateVector
messageYjsSyncStep2 && messageYjsUpdate:
VarUint8Array: update
messageAwareness:
VarUint8Array: updateEvery message starts with an integer identifying the type of message. Depending on the type of message other data is expected.
On both the client in my fork of y-websocket and in my custom server I define a new message type messageSubDocSync = 4 which is functionally identical to messageSync except for an additional variable length string for subdoc related metadata–currently only the ID of the subdocument.
messageSubDocSync:
<subdoc>
VarString: subdocID
</subdoc>
VarUint: messageType
messageYjsSyncStep1:
VarUint8Array: encodedStateVector
messageYjsSyncStep2 && messageYjsUpdate:
VarUint8Array: updateUnder the hood the y-websocket provider keeps a map of id’s to subdocuments. When a change is received the provider behaves nearly identically to a regular document with the exception of decoding the metadata and finding the in memory subdocument to operate on (rather than the root document).
Those familiar with the yjs internals will realize that each document, root or subdocument, is still synced individually rather then syncing the root document with all of the subdocuments already loaded. This is an intentional decision, I want the ability to only sync some of the subdocuments on command. You can imagine several use cases for this. Currently I mainly use it for lazy loading subdcouments as they come into view.
This example shows how you would implicitly load subdocuments. In this example, it automatically loads all subdocuments, but you can see how it could be adapted for more complicated use cases.
ydoc.on("subdocs", ({ added }) => {
added.forEach((subdoc) => {
//calling load() on an empty subdocument object triggers the y-websocket
//provider to begin syncing by sending a `messageSubDocSync`
subdoc.load();
});
});Server
The server is currently pretty simple. It keeps track of each update as the server receives it, delivers it to any other client’s currently subscribed to updates for that document and then persists it in postgres. Currently the database model is incredibly simple:
export class Operation {
@PrimaryGeneratedColumn()
id?: number; //for loosely "enforcing" order of the updates
@Column()
docid: string;
@Column({
type: "bytea",
})
op: Uint8Array;
}This is a setup I am pretty happy with for now since it makes retrieving documents from the database extremely simple. By retrieving a list of all updates for a given document and applying them to each other you end up with a complete view of the document.
export const initializeSubDoc = async (doc: WSSharedDoc) => {
const persistedUpdates = await getUpdates(doc);
const dbYDoc = new Y.Doc();
doc.subdoc = true;
dbYDoc.transact(() => {
for (const u of persistedUpdates) {
Y.applyUpdate(dbYDoc, u.op);
}
});
Y.applyUpdate(doc, Y.encodeStateAsUpdate(dbYDoc));
};I am in the process of re-architecting the websocket server to run on the JVM to make easier use of kafka which a number of figment features rely on.
The server does a bunch of other clever thing over the websocket connection that are Figment specific, I’ll be writing about it sometime soon.
Editor bindings
Figment uses prosemirror as the basis for our editor. Yjs already has excellent prosemirror bindings, it was missing a full implementation for a feature that would usually not be used when not using subdocuments, as well as lending itself to some footguns in implementing subdocuments. I have a pull request open to merge these changes upstream.
Demo
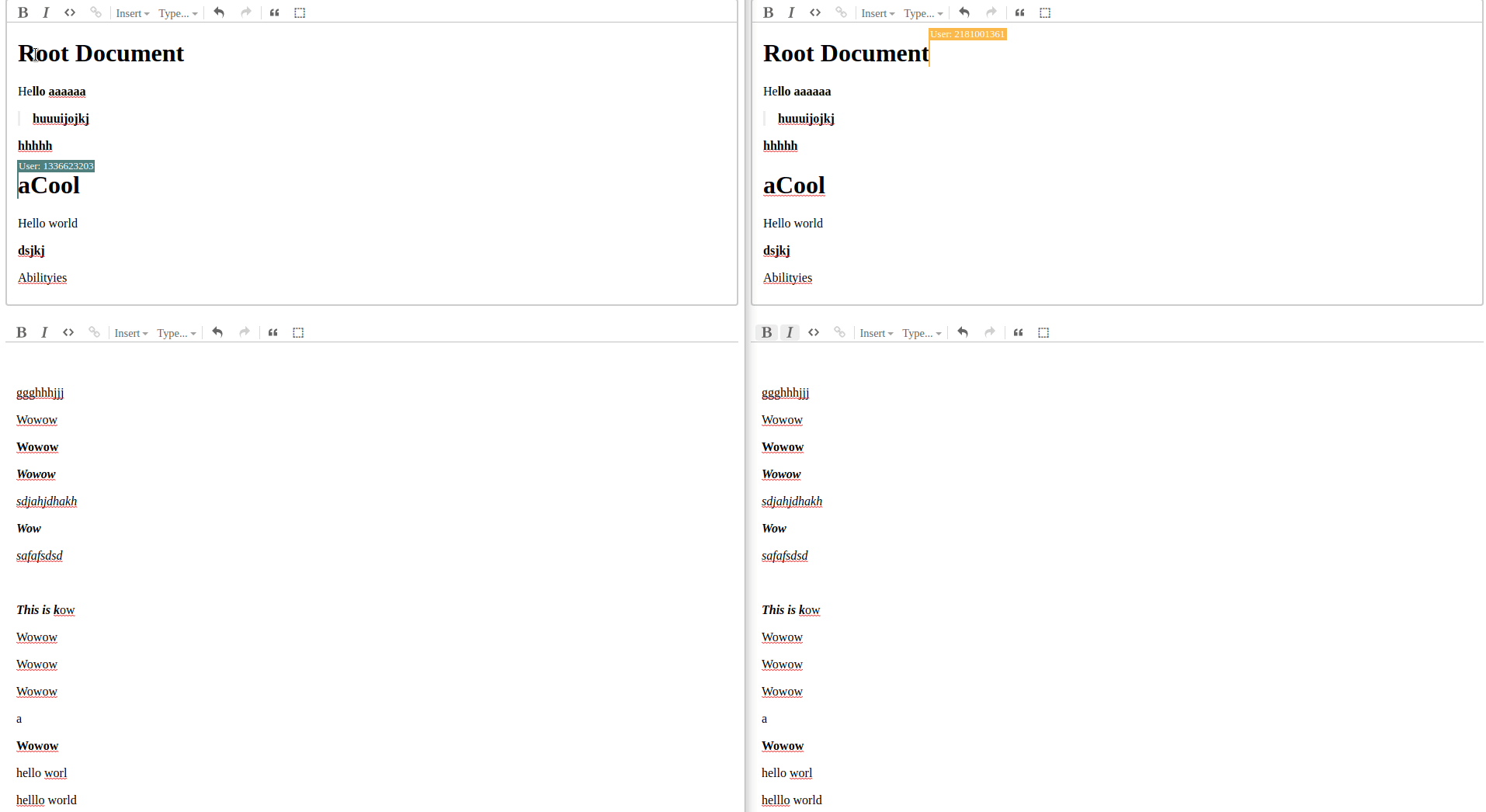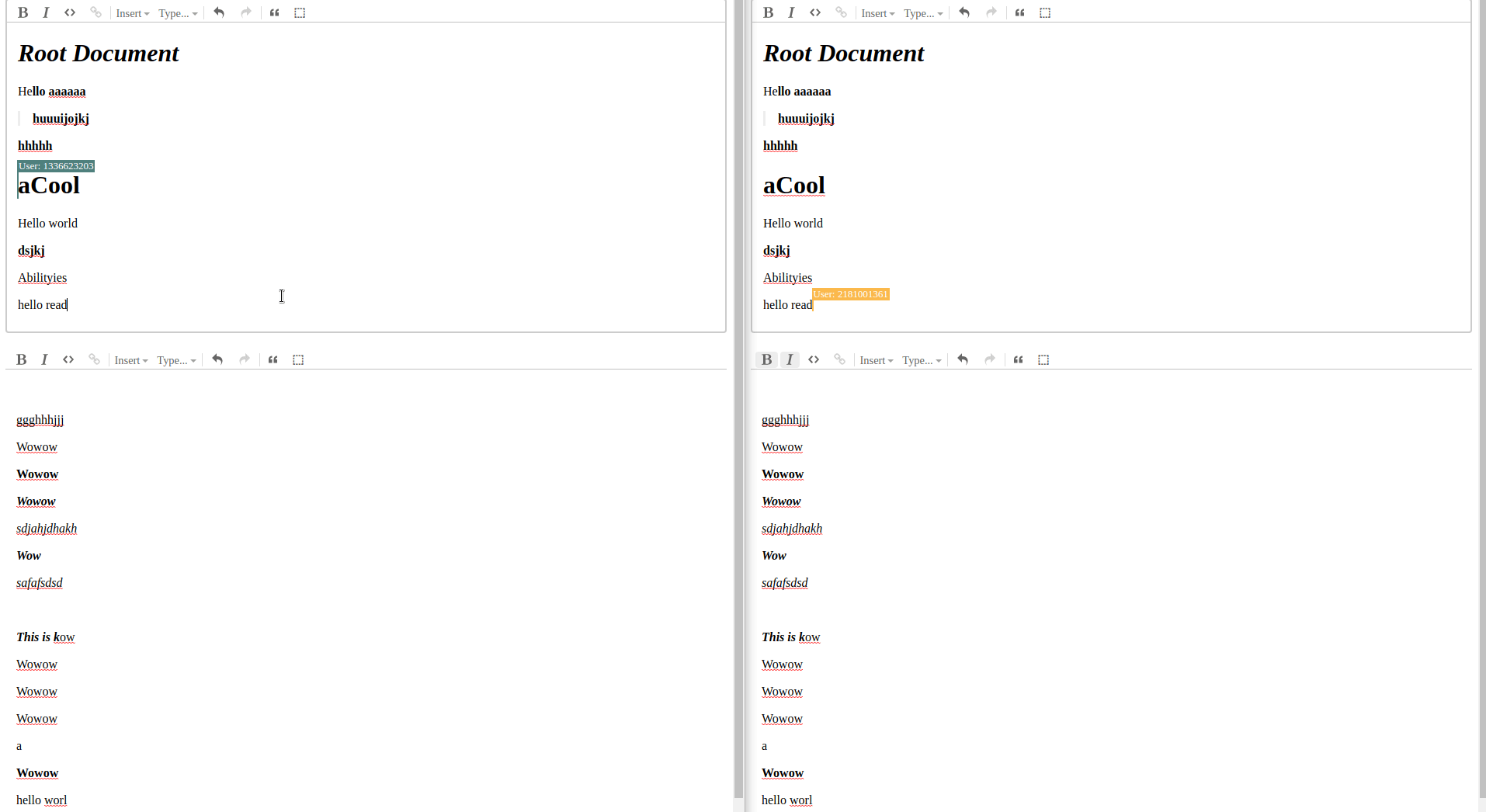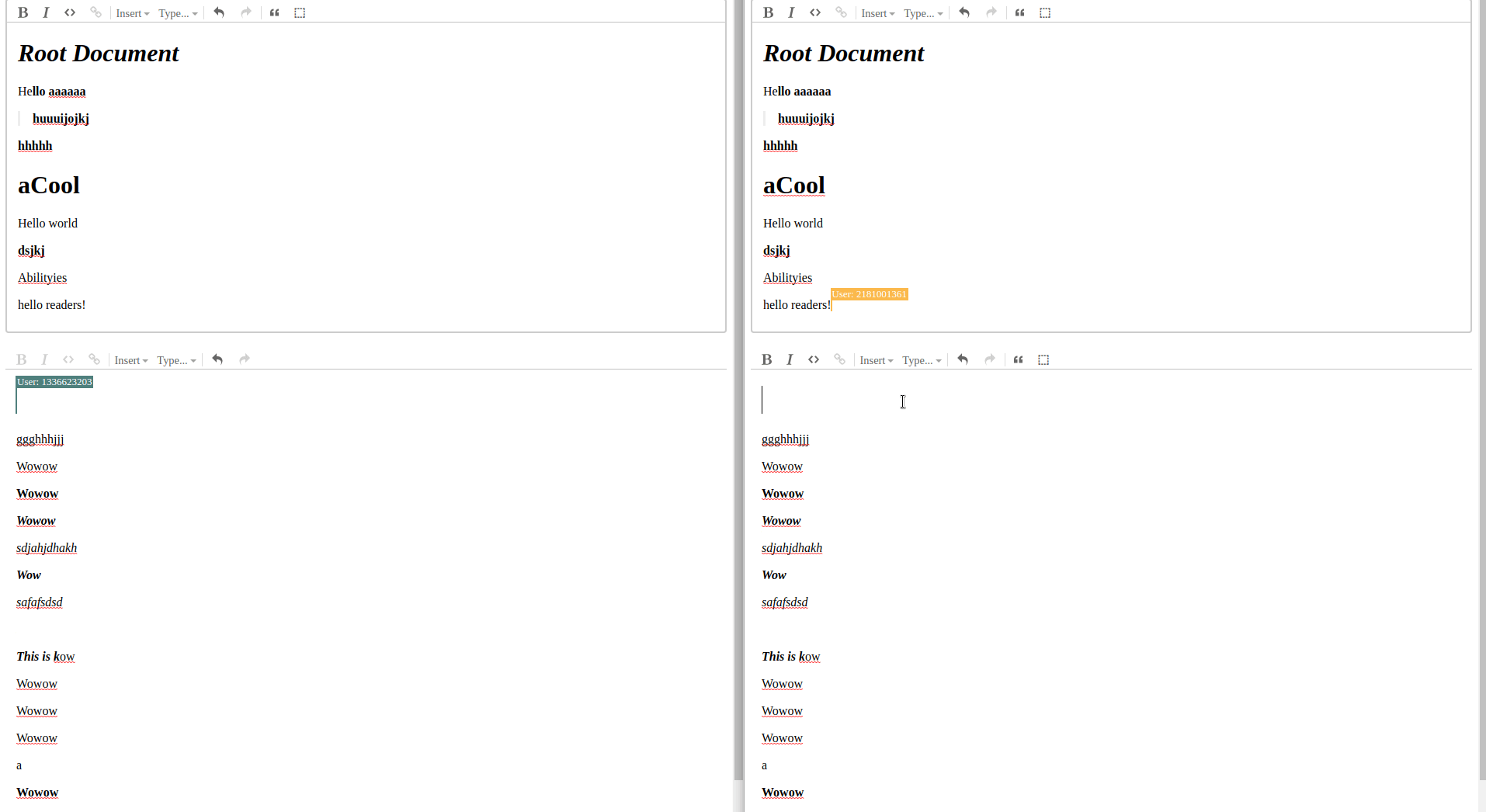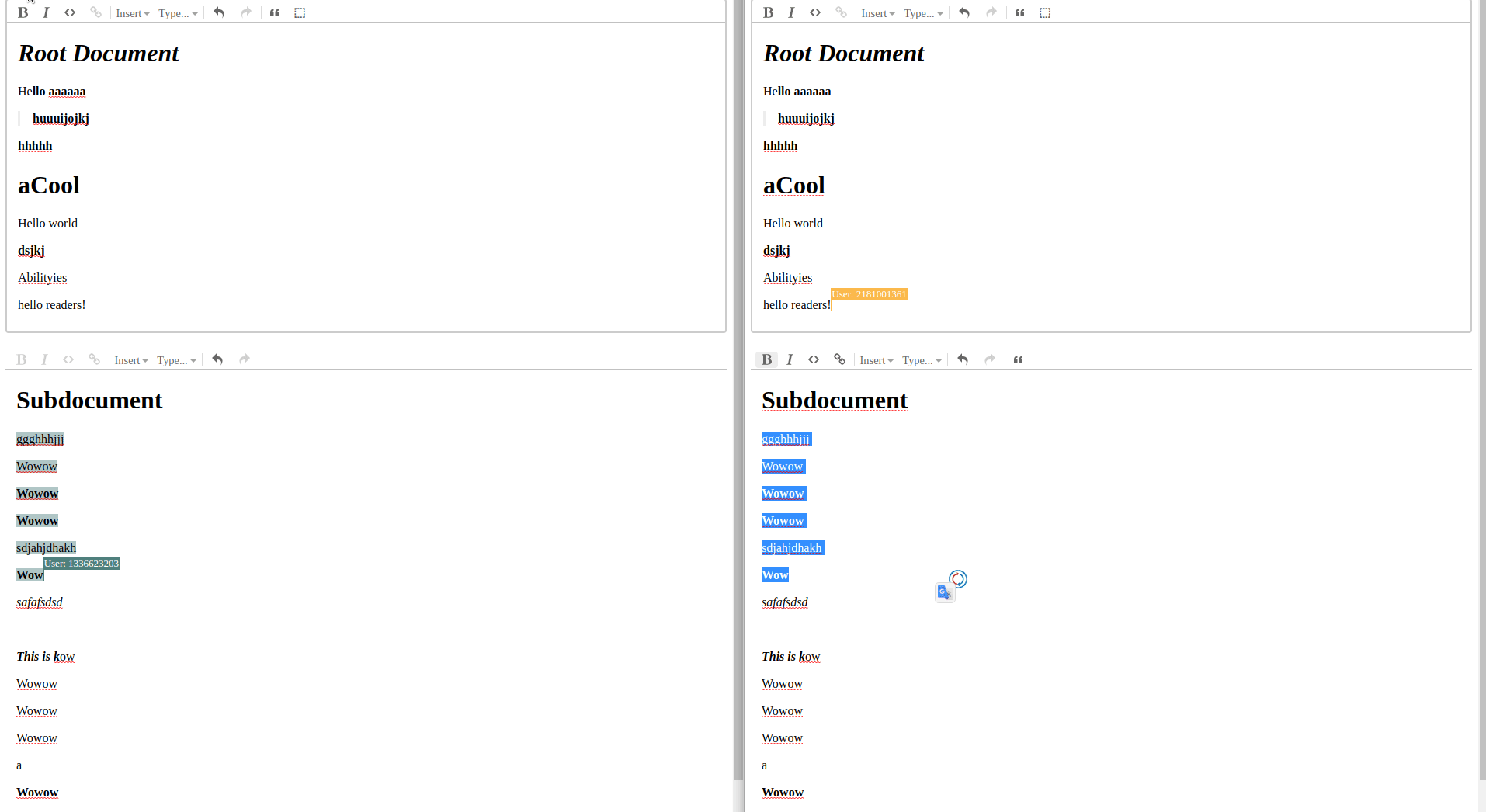
This is hopefully the first in a series of posts on how I tackled some of the problems I came across in figment. None of this is necessarily the right or best way, in fact it probably isn’t, I just hope it can be a resource to someone in my position from a few weeks ago on how to work with yjs persistence and subdocuments.
My y-websocket fork can be found here: https://github.com/DAlperin/y-websocket, I hope to update the reference server implementation to demo how I’ve built in subdocuments in case it’s helpful for anyone. Not sure if this is worth upstreaming yet since a lot of it makes pretty infrastructure specific assumptions and I believe dmonad is working on a better official implementation.
My y-prosemirror changes can be found here: https://github.com/yjs/y-prosemirror/pull/88
Feel free to reach out. I can be found at dov(at)dov(dot)dev over email or @dalperin:matrix.org on matrix.